HPC 入门
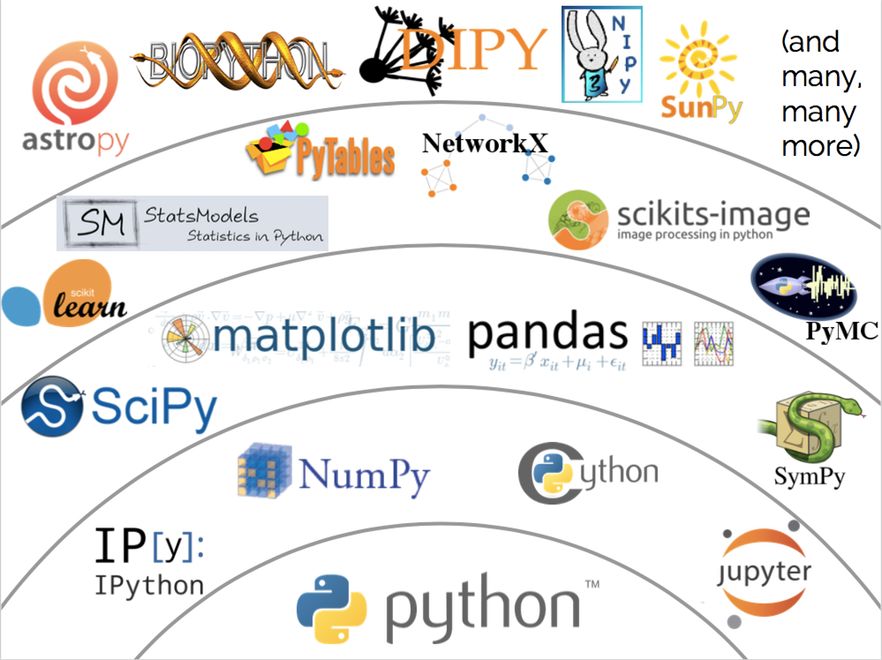
MLSys 软件栈:
- vllm | sglang | Megatron-LM | DeepSpeed | huggingface | ollama
- transformers | flash-attention | x-formers | accelerate
- scipy | sklearn | pytorch | tensorflow | jax | triton
- cpython | cyphon | numpy | cupy | cuda
- blas | openblas | mkl | cublas | lapack | eigen | libdivide
- openssl | sqlite | openmp | mpi …
CUDA 的线程组织结构: Device -> Grid -> Block (对应一个 SM) -> Warp -> Thread
CUDA 的内存层次结构
- Thread 级别: Local Memory, Registers
- Block 级别: Shared Memory
- Device 级别: Global Memory, Constant Memory, Texture Memory
__global__修饰符用于声明在 GPU 上执行的函数, 返回 voidMPI 消息传递模型
OpenMP 共享内存模型
GPU
- GPU Die
- HBM stack, ~80GB
- Silicon Interposer: PCB 上连接 GPU Die 和 HBM stack, 提供高带宽的通信
GPU Die
- SM, 80~296 个
- L2 Cache, 40MB
SM (Streaming Multiprocessor)
- 一个超宽 SIMD 单元 + 硬件多线程
- 一次发射 4 个 warp = 128 个 thread
- CUDA Cores: 做通用计算, 64~128 个
- Tensor Cores: 做 MMA, 4 个
- 寄存器: 256KB SRAM, 可以用作 Shared Memory 和 L1 Cache
- Tensor Memory Accelerator: 类似 DMA 引擎, >=H100
Warp
- 32 个 thread 组成一个 warp
- 编程模型: SIMT (Single Instruction Multiple Threads)
- 共享一个 PC, 所有 thread 共享指令流, 如果控制流不同, 会退化成 Masked 串行执行 divergence
- 32 个线程逻辑上独立,各有自己的寄存器、各自的内存地址
Block
- 1024 个执行同一任务的 thread 构成的逻辑 Batch
- 一定在同一 SM 上执行,共享 SM 的寄存器、共享内存、Barrier
Grid
- 一个 GPU 计算任务
- 一个 Grid 包含 gridDim.x * gridDim.y * gridDim.z 个 Block
- 每个 Block 包含 blockDim.x * blockDim.y * blockDim.z 个 thread
NVLink
- 用于连接多个 GPU, 提供高带宽的通信
- 有 Bridge、Cable、Switch 形态
Kernel 函数的调用语法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36__device__ retarg device_fn(arg1, arg2, ...) {
// impl
}
__global__ void kernel_fn(arg1, arg2, ...) {
// Grid 里的 Block 总数
int num_blocks = gridDim.x * gridDim.y * gridDim.z;
// 每个 Block 里的 Thread 数
int threads_per_block = blockDim.x * blockDim.y * blockDim.z;
// Grid 里的 Thread 总数
int total_threads = num_blocks * threads_per_block;
// Block 在 Grid 内的线性索引
int block_index = blockIdx.z * (gridDim.x * gridDim.y)
+ blockIdx.y * gridDim.x
+ blockIdx.x;
// Thread 在 Block 内的索引
int thread_local_index = threadIdx.z * (blockDim.x * blockDim.y)
+ threadIdx.y * blockDim.x
+ threadIdx.x;
// Thread 在 Grid 内的线性索引
int thread_global_index = block_index * threads_per_block + thread_local_index;
// device_fn() impl...
}
void launch_kernel() {
dim3 gridDim(128, 1, 1);
dim3 blockDim(10, 10, 10);
// 启动一个任务,包含 128 个 Block, 每个 Block 1000 个 thread
kernel_fn<<<gridDim, blockDim>>>(arg1, arg2, ...);
}bank conflict
- 多个 thread 访问同一个 bank 导致的内存访问冲突
- 解决方法: 增加 bank 数量, 每个 thread 访问不同的 bank
warp divergence
- 多个 thread 在一个 warp 内, 控制流不同, 导致的串行执行
- 解决方法: 增加 warp 数量, 每个 warp 包含 32 个 thread
树形 reduce 算法
- Warp 级别: shuffle xor sync, shuffle down sync
- Block 级别: reduce
Flash Attention
Paged Attention
Block Attention