[SysML'18] Compiling Machine Learning Programs via High-Level Tracing (JAX) 论文阅读
Jax = Autograd + XLA
Autograd = 类似 PyTorch 的 autograd。
XLA = Google 的加速器编译器,支持 CPU/GPU/TPU,提供数组级优化和融合能力。
#0. 摘要
本文介绍了 JAX:一个面向领域的 tracing JIT 编译器,能够从纯 Python 和 NumPy 编写的机器学习程序生成高性能的加速器代码。JAX 借助 XLA 编译基础设施为"最适合加速"的子程序生成优化代码,这些优化后的子程序可以被任意 Python 代码调用和编排。由于 JAX 与 Autograd 完全兼容,它支持对 Python 函数进行任意阶的前向和反向自动微分。由于 JAX 支持结构化控制流,它能够为复杂机器学习算法生成高性能代码。将 JAX 与 Autograd 和 NumPy 结合,可以得到一个既易于编程、又高度高性能的 ML 系统,能够同时面向 CPU、GPU 和 TPU,并可扩展到多核 Cloud TPU。
#1. 引言
机器学习的飞速发展在很大程度上由可用算力(FLOPs)的爆炸式增长所驱动。自 AlexNet 在双 GPU 上取得突破以来,研究者手中的 FLOPs 数量和使用便捷性都显著提升。JAX 的目标是继续推进这一方向——让研究者用熟悉的 Python 工具链(NumPy 做数值计算、Autograd 做自动微分)写出的程序能够被自动编译并扩展到加速器乃至超算规模。
然而,最大化算力访问 与 研究友好的可编程性 常常彼此冲突:
- Python 这类动态语言写代码方便,但过于自由,难以做优化代码生成。
- 有效的硬件加速(尤其是 DGX-1、Cloud TPU 这样的新硬件)需要大量静态信息。
JAX 从一个经验观察出发来化解这一矛盾:ML workload 通常由大块、可加速、**纯粹且静态组合(pure-and-statically-composed, PSC)**的子程序构成,由动态逻辑负责整体编排。一个函数若无副作用则是"纯"的;若它能被表示为在一组原语上的静态数据依赖图,则称其相对于该原语集合是"静态组合"的。只要原语本身可加速(如数组级数值核与受限控制流),那么 PSC 子程序就是加速的理想候选——它们把原始 Python 程序中"不必动态"的部分划出来,剥离掉所有不必要的动态性。
JAX 是一个 JIT 编译器,它结合 high-level tracing 与 XLA 编译基础设施为 PSC 子程序生成代码。这里的 tracing 在两个意义上都是 “high-level” 的:
- 它作为源语言中的用户级代码实现,而不是嵌入在源语言运行时中;
- trace 中的原语不是 VM-level 的基础数据操作,而是 library-level 的数值函数——如矩阵乘、卷积、沿轴归约、逐元素操作、多维索引/切片等。
JAX 构建在与 Autograd 共享的 tracing 库之上,因此能够识别自身的操作作为原语;NumPy 的数值函数也被注册为原语。结果是:JAX 能为用熟悉的 NumPy 写成、并涉及任意阶前向/反向自动微分的 Python 函数生成代码。后端方面,JAX 使用 XLA 做数组级程序优化与代码生成。与其他系统"提供固定集合的手写数值核"不同,JAX 通过 trace-compile PSC 子程序,自动从已有核中派生出新核,覆盖 XLA 支持的所有目标架构。
JAX 这个名字是 “Just After eXecution” 的缩写 —— 编译一个函数前,需先在 Python 中观察它执行一次。
下面是一个典型用法示例:用 JAX 实现一个全连接网络。
1 | import autograd.numpy as np |
#2. 系统设计
JAX 的设计建立在"ML workload 通常由 PSC 子程序主导"这一观察上。因此,trace formation 只要求用户在 PSC 入口函数上打一个注解——即假设 PSC 性质成立的 Python 函数。ML 代码中此类函数通常容易识别,研究者只需给它加上 jit_ps 装饰器即可。手工注解对非专家用户和"零工作负载知识"的优化是一种挑战,但它能立刻给专家用户带来收益,并作为一个系统研究项目展示 PSC 假设的威力。
Trace caching:JAX 为被 trace 的计算生成一份单态(monomorphic)签名——新的数组元素类型、数组维度或元组成员会触发重新编译。
Trace miss 时的行为:JAX 会执行对应的 Python 函数,并将其执行 trace 成一张带有静态数据依赖的原语函数图。现有原语包括:
- 数组级数值核:NumPy 函数以及卷积、窗口化归约等;
- 受限控制流函数:函数式的
while_loop、cond(if-then-else)等。这些控制流原语相较于 Python 语法控制流不那么熟悉,但它们保持了 PSC 属性,允许用户把控制流也 stage 到编译计算中; - 函数式分布式原语:如
iterated_map_reduce。
原语集合在 Python 中定义,是可扩展的——新原语只需提供一个翻译规则,将其映射到对应的 XLA 计算。
代码生成:JAX 把 trace 翻译为 XLA HLO——一种为高度可加速的数组级数值程序建模的中间语言。粗略地说,JAX 可以被看作是把 XLA 编程模型"提升"到 Python 中的系统,使得可加速子程序能以 XLA 的能力运行,同时仍然允许动态编排。下面是一些翻译规则示例(摘自原文 Listing 2):
1 | def xla_add(xla_builder, xla_args, np_x, np_y): |
与 Autograd 的兼容性也使得前文示例那种"对 loss 求梯度 + JIT 编译"的写法可以无缝实现。
#3. 实验与示例
#3.1 数组级融合(Array-level fusion)
为了展示 JAX + XLA 提供的数组级代码优化与算子融合能力,作者编译了一个带 SeLU 非线性的全连接层,并展示了 JAX trace 与 XLA HLO 图。图 1 显示:融合后整个网络层的所有 ops 被 fuse 到 GEMM 之中——灰色框圈出了融合结果。
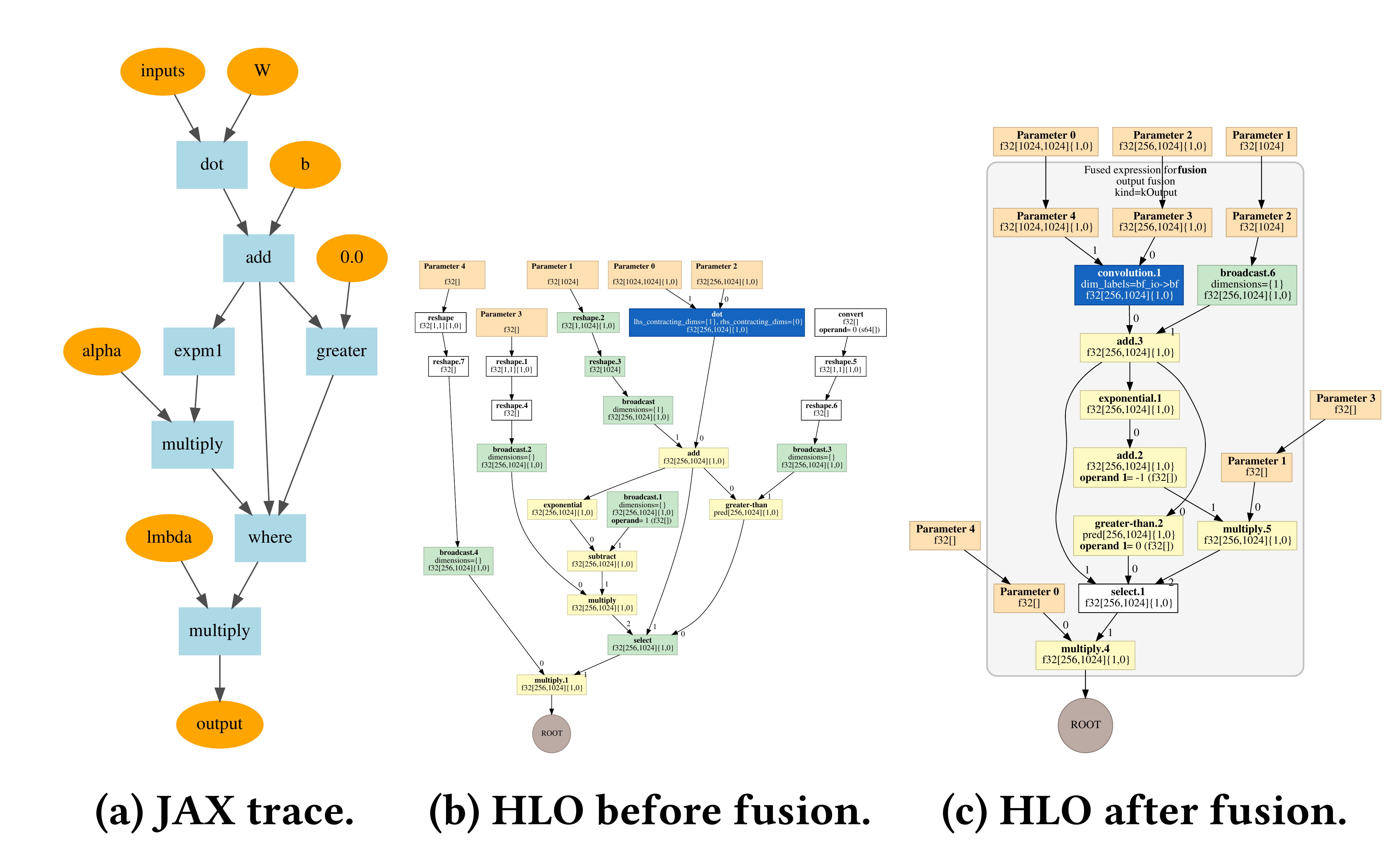
图 1:带 SeLU 非线性的全连接层的 XLA HLO 融合。(a) JAX trace;(b) 融合前 HLO;© 融合后 HLO,灰色框标记被 fuse 到 GEMM 中的所有 ops。
#3.2 CPU 上的 Truncated Newton-CG 优化
作为 CPU benchmark,作者实现了一个 truncated Newton-CG 优化算法:外层做近似 Newton-Raphson 更新,内层用共轭梯度(CG)算法,并在残差范数降到阈值以下或达到最大内层迭代数时截断。与单线程 Python 执行对比,JAX 编译后的执行时间在多个小规模示例上取得显著加速(表 1)。
| 问题 | Python | JAX | 加速比 |
|---|---|---|---|
| 凸二次(convex quadratic) | 4.12 s | 0.036 s | 114× |
| 隐马尔可夫模型拟合(HMM) | 7.79 s | 0.057 s | 153× |
| 逻辑回归拟合 | 3.62 s | 1.19 s | 3× |
注意:XLA 在部分 CPU 示例上的编译时间较慢,但预计未来会有显著改善;表中给出的是热身后的运行时。
#3.3 GPU 上训练卷积网络
作者实现了一个全卷积 CIFAR-10 网络(仅含卷积 + ReLU),JAX 编译了单步 SGD 更新并从纯 Python 循环中调用,取 100 次试验中最小平均 wall-clock 步时间。作为参照,同样算法的 TensorFlow 实现在相似 Python 循环中被调用。Benchmark 环境:HP Z420 工作站,CUDA 8 + driver 384.111。
| 后端 | 相对 | |
|---|---|---|
| TF:GPU | 40.2 ms | 1× |
| JAX:GPU | 41.8 ms | 1.04× |
#3.4 Cloud TPU 可扩展性
在 Cloud TPU 核心上,对全局 batch 进行 JAX 并行化表现出线性加速(图 2 左)。在每 replica 固定 minibatch 的情况下, 几乎不受 replica 数量影响(变动在 2 ms 以内,图 2 右)。实验使用的是一个 4 芯片、每芯片 2 核的 Cloud TPU 配置——因此 比 更高效,因为片内通信比片间通信更快; 处的异常来自 XLA all-reduce 实现细节。
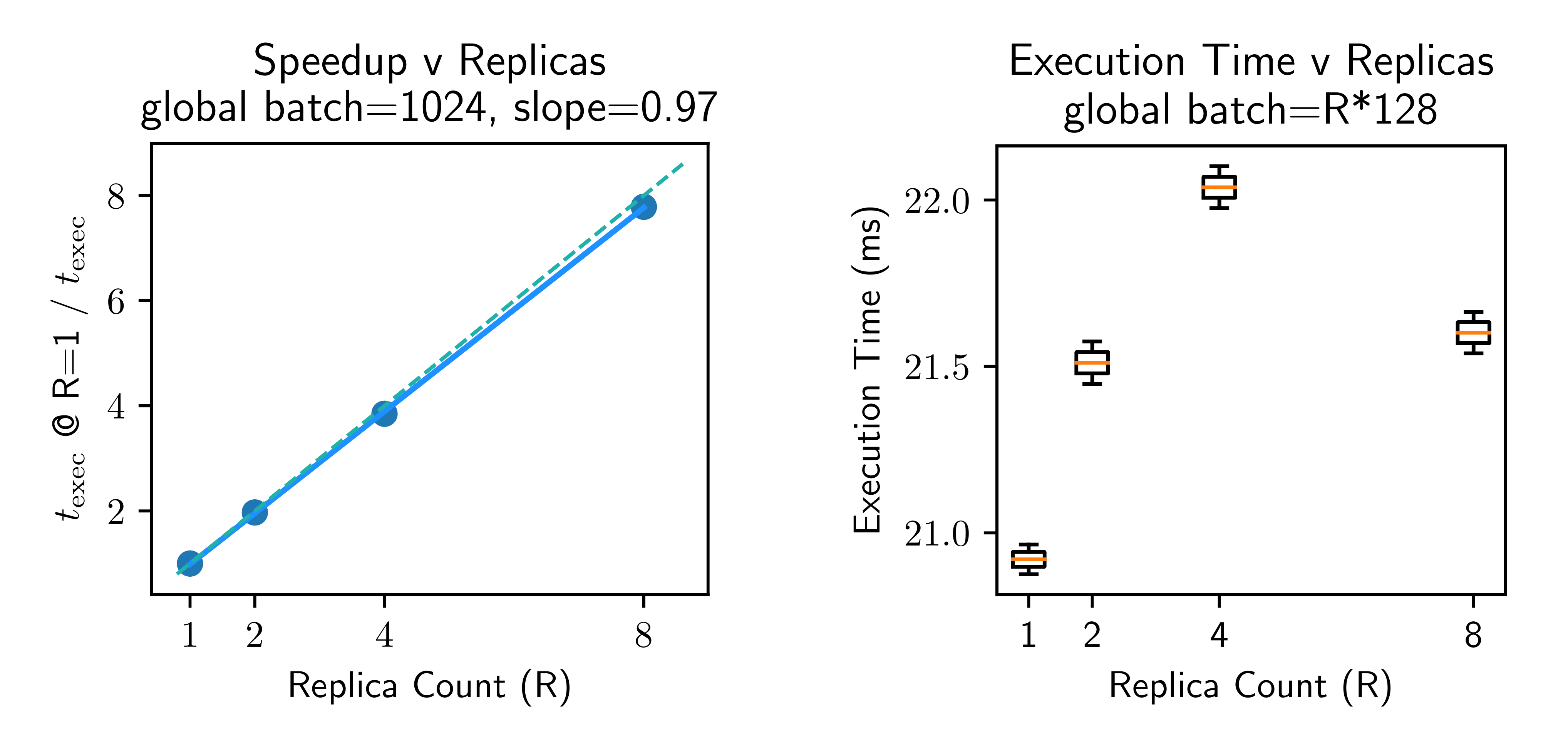
图 2:Cloud TPU 上 ConvNet 训练步的可扩展性。左:Speedup 对 replica 数,全局 batch=1024,斜率 0.97;右:Execution Time 对 replica 数,全局 batch = R×128。
#4. 小结
JAX 通过 high-level tracing + XLA 后端,将"Python/NumPy 开发体验"与"加速器级性能"这对看似矛盾的目标调和起来:
- PSC 假设 抓住了 ML workload 的结构特点,把可加速部分从动态编排中分离;
- user-level tracing + 可注册原语 让系统对新算子、新控制流、新硬件都有扩展性;
- 与 Autograd 完全兼容,使任意阶自动微分 + JIT 编译成为一行装饰器的事;
- XLA HLO 后端 带来数组级融合、跨 CPU/GPU/TPU 的统一目标,以及 Cloud TPU 上的近线性扩展。
这篇短论文勾勒出的系统哲学——tracing 作为 user-level 变换 + XLA 作为统一的数组编译器——在后来发展为如今广泛使用的 JAX 生态(jit、grad、vmap、pmap 等函数变换的组合)。
#参考资料
- R. Frostig, M. J. Johnson, C. Leary. “Compiling machine learning programs via high-level tracing.” SysML 2018. PDF(Frostig-Johnson-Leary-2018-Compiling-ML-via-high-level-tracing.pdf)
- Autograd: https://github.com/HIPS/autograd
- XLA: https://developers.googleblog.com/2017/03/xla-tensorflow-compiled.html