[CIKM'24] TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling 论文精读
TWIN 让 CP-GSU 与 ESU 用一致的目标注意力, 把可建模长度推到. 但用户全生命周期行为可达, 即便 TWIN 的高效注意力也吃不下.
快手发现: 高活用户 (- 行为) 只占 12%, 却贡献了 60% 的 app 使用时长 —— 正是这批人的超长历史最该被完整建模, 而 TWIN 只覆盖了最近几个月.
TWIN-V2 的思路是分治压缩: 离线把相似行为层次聚类成簇 (一个簇 = 一个 “虚拟物品”), 把 行为压到约 10%; 在线用 cluster-aware target attention 在簇上建模, 并按簇大小重加权 (簇越大代表兴趣越强). 覆盖全生命周期, 快手 4 亿日活主流量上线.
#摘要
长期兴趣建模对大规模推荐的 CTR 预估越来越重要. SIM、TWIN 等用两级方法 (GSU 检索 + ESU 精算) 解决效率问题. 但用户行为序列横跨整个生命周期, 规模可达, 目前没有有效方案能完整建模如此庞大的兴趣.
本文提出 TWIN-V2, 是 TWIN 的增强版, 用分治 (divide-and-conquer) 方法压缩生命周期行为, 挖掘更准确、更多样的用户兴趣. 具体地: 离线阶段用层次聚类把生命周期行为中特征相似的物品聚成一个簇; 通过限制簇大小, 可把 级以上的行为序列压到在线 GSU 检索可处理的长度; cluster-aware target attention 提取用户全面、多面的长期兴趣, 使推荐结果更准更多样. 已部署于快手主流量 (约 4 亿日活).
#1. 引言与动机
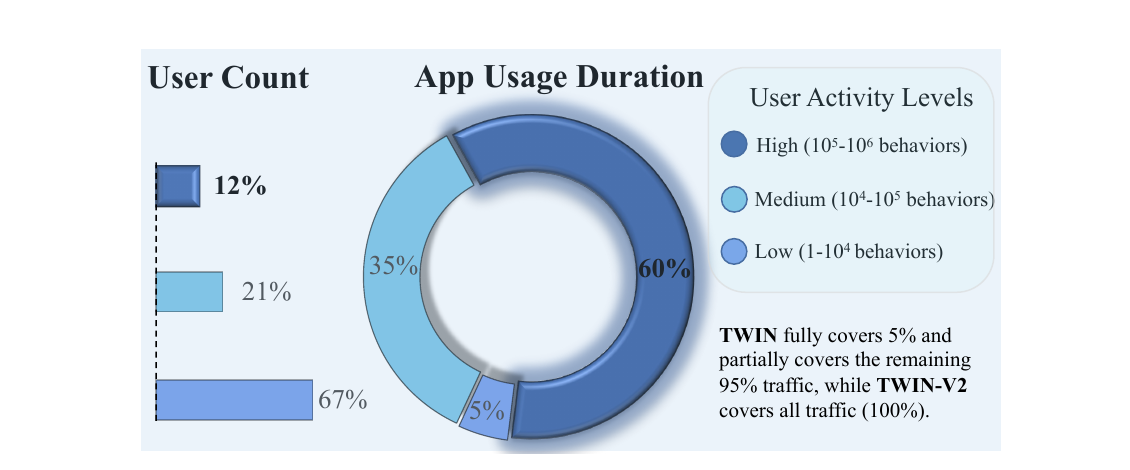
图 1. 快手用户数量占比 vs app 使用时长占比. 按行为数把用户分成三档: 高活 (-)、中活 (-)、低活 (-). 高活用户仅占 12%, 却贡献 60% 的使用时长. TWIN 只完整覆盖 5% 流量、部分覆盖其余 95%, 而 TWIN-V2 覆盖全部 (100%).
TWIN 已经把一致的目标注意力扩展到, 但全生命周期行为可达:
- 直接对 行为做 GSU 检索, 即便是 TWIN 的高效注意力也算不过来、存不下;
- 而恰恰是高活用户的超长历史最有价值 (图 1).
TWIN-V2 的洞察: 用户会反复观看大量相似视频 (一个 NBA 球迷历史里可能有数百个篮球视频). 自然的想法是把相似物品聚成簇, 用一个簇代表许多相似物品, 从而压缩序列长度. 模型分两部分:
- 离线: 层次聚类把生命周期行为聚成簇, 从每个簇抽取特征形成一个虚拟物品 (virtual item);
- 在线: 用 cluster-aware target attention 在簇上建模长期兴趣, 注意力分按对应簇大小重加权.
#2. TWIN-V2 模型
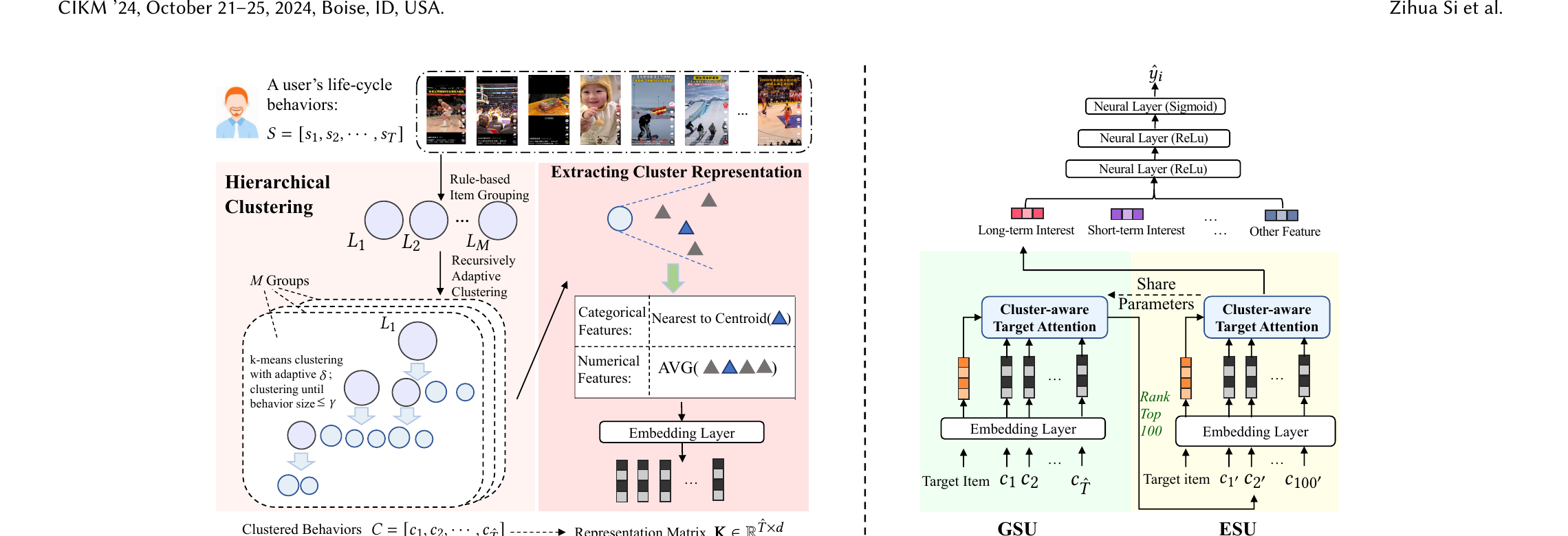
图 2. TWIN-V2 总览. 左: 离线组件压缩生命周期行为并抽取簇特征. 右: 在线组件用两级方法 (GSU + ESU) 从生命周期行为中捕捉兴趣, 两级都以聚类后的行为为输入.
#2.1 离线: 生命周期行为的层次聚类
把用户 的全部历史表示为 ( 可达). 用压缩函数 把长度 压到:
其中 是第 个簇 (一组聚在一起的物品). 层次聚类 (算法 1) 分两步:
① 按播放完成度分组: 短视频里, 视频的播放完成比可视为用户兴趣强度的指标. 先按播放完成比 把行为分成 组 (论文, 即把比例区间五等分). 这样保证最终每个簇内播放比相对一致 —— 否则 k-means 只看 embedding 会导致簇内分布不均衡.
② 递归自适应聚类: 对每组用 k-means 递归聚类, 直到每个簇内物品数不超过. 关键设计:
- 聚类用的 embedding 来自推荐模型 —— 即聚类由协同过滤信号引导, 而非纯内容相似;
- 簇数 动态设定 ( = 物品数的 0.3 次方), 适应不同规模的历史;
- (最大簇大小); 实测平均簇大小约, 故, 把序列压缩约 90%.
#2.2 离线: 抽取簇表示 (虚拟物品)
每个簇用一个虚拟物品表示, 物品特征分两类:
- 数值特征 (视频时长、播放时长): 取簇内所有物品的平均:
- 类别特征 (视频 ID、作者 ID): 平均无意义, 取簇内离质心最近的物品来代表:
整个簇 由聚合的虚拟物品特征 表示, 过 embedding 层后得到向量.
#2.3 在线: Cluster-aware Target Attention
沿用 TWIN 的高效注意力 (固有特征 / 交叉特征 拆分), GSU 与 ESU 都以簇为输入. 先算相关性分:
簇大小重加权: 不足以表达簇与目标的关系 —— 因为各簇物品数不同. 若两个簇相关性相同, 物品更多的簇应更重要 (更多物品意味着更强的用户偏好). 于是按簇大小调整:
其中 是各簇的大小, 为簇 的物品数.
- GSU 阶段: 用 从 个簇中选 Top-100 最相关的簇;
- ESU 阶段: 对 100 个簇按相关性加权池化:
注意 可改写为 (每个簇的相关性 被簇大小 重加权):
采用 4 头多头注意力得到最终长期兴趣. 与 TWIN 的关键差异: 现有工作 ESU 取 Top-100 行为, 而 TWIN-V2 取 Top-100 簇 —— 这些簇覆盖的行为远超 100 个, 让 ESU 能建模更广的行为谱, 实现生命周期级建模.
#2.4 部署
离线 “层次聚类 Runner” 与近线训练器协同, 把聚类结果与簇表示同步到 embedding server; 在线收到请求后查投影、走 GSU→ESU. 整体把生命周期行为的存储与计算开销降低约 90%, 支撑 行为建模.
#3. 实验
数据集: 快手工业数据 (3.455 亿用户, 单用户历史最长截到 100,000). TWIN-V2 压缩到约 10% → GSU 输入约 10,000 簇; 其他两级模型 GSU 输入限 10,000 行为; DIN/Avg-Pooling 取最近 100.
#3.1 整体性能
表 3. 与 SOTA 对比 (5 天均值; AUC 提升 0.001 即显著):
| Method | AUC | GAUC |
|---|---|---|
| Avg-Pooling | 0.7855 | 0.7168 |
| DIN | 0.7873 | 0.7191 |
| SIM Hard | 0.7901 | 0.7224 |
| ETA | 0.7910 | 0.7243 |
| SIM Cluster | 0.7915 | 0.7253 |
| SDIM | 0.7919 | 0.7267 |
| SIM Cluster+ | 0.7927 | 0.7275 |
| SIM Soft | 0.7939 | 0.7299 |
| TWIN | 0.7962 | 0.7336 |
| TWIN-V2 | 0.7975 | 0.7360 |
| Improv. (vs TWIN) | +0.16% (+0.0013) | +0.33% (+0.0024) |
TWIN-V2 较第二名 TWIN 提升 +0.0013 AUC / +0.0024 GAUC. 且 GAUC 的相对提升大于 AUC —— 说明提升覆盖各类用户 (尤其高活用户群), 而非只在整体样本上更好.
#3.2 消融: 层次聚类方式 (表 4)
对比三种聚类: Balanced&Binary ( 且强制均衡)、Binary ()、Adaptive (本文, 动态):
| 方法 | 簇精度 (簇内余弦相似) | 单用户聚类耗时 (秒) |
|---|---|---|
| Balanced&Binary | 0.765 | 1.010 |
| Binary | 0.789 | 1.201 |
| Adaptive (ours) | 0.802 | 0.750 |
本文的自适应聚类精度最高、耗时最短. 另一组消融把 换回 (去掉簇大小重加权) 会掉点, 验证了按簇大小调整注意力分的有效性.
#3.3 在线 A/B
表 5. 三场景相对提升 (对比 TWIN; 0.1% 即显著):
| 场景 | Watch Time | Diversity |
|---|---|---|
| Featured-Video Tab | +0.672% | +0.262% |
| Discovery Tab | +0.800% | +0.740% |
| Slide Tab | +0.728% | +0.005% |
TWIN-V2 在观看时长上全面超过 TWIN; 由于建模了更长历史, 还挖掘出更多样的兴趣, 推荐结果更丰富多样 (diversity 提升).
#4. 总结
TWIN-V2 把可建模长度从 TWIN 的- 推到全生命周期, 核心是 “分治压缩”:
- 离线层次聚类: 按播放完成度分组 + CF embedding 引导的自适应 k-means, 把相似行为聚成簇 (虚拟物品), 压缩约 90% 存储与算力; 类别特征取最近质心、数值特征取均值.
- 在线 cluster-aware target attention: 沿用 TWIN 的高效注意力 + 一致性, 并用 按簇大小重加权, Top-100 簇覆盖远超 100 个行为.
这是 TWIN 系列的自然延伸 —— 当一致的注意力 (TWIN) 仍受限于序列长度时, 用聚类把 “更长” 换成 “更短但等价” 的簇序列.
整条兴趣建模主线:
| 论文 | 解决的问题 |
|---|---|
| DIN (KDD’18) | target-aware 注意力, 突破定长向量 |
| DIEN (AAAI’19) | 兴趣随时间演化 (GRU + AUGRU) |
| SIM (CIKM’20) | 终身超长序列 (检索式 GSU+ESU) |
| TWIN (KDD’23) | 两级检索的一致性 (CP-GSU = ESU) |
| TWIN-V2 (CIKM’24) | 全生命周期 (聚类压缩 + 簇感知注意力) |
#参考资料
- TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou (arXiv:2407.16357, CIKM’24)
- TWIN: TWo-stage Interest Network (KDD’23)
- SIM: Search-based Interest Model (CIKM’20)