[KDD'23] TWIN: TWo-stage Interest Network 论文精读
SIM 开创了 GSU+ESU 两级检索建模终身行为,但 TWIN 指出它有个根本缺陷: 两阶段的相关性度量不一致.
- ESU 用昂贵但精准的目标注意力 (Target Attention);
- GSU 为了省算力,用的却是另一套粗糙度量 (类目匹配 / 内积 / LSH 哈希).
结果: GSU 粗筛回来的 Top-100 里,只有约 40 个命中 ESU 眼中真正的 Top-100 – GSU 漏掉了 ESU 认为重要的行为,上限被第一阶段卡死.
TWIN 的解法是让两阶段成为 “双胞胎”: CP-GSU 用与 ESU 完全相同的注意力 (结构 + 参数)。难点是 MHTA 太贵只能跑 100 个行为,TWIN 通过行为特征拆分 (固有特征预计算缓存 + 交叉特征压成 1 维偏置) 把它扩展到 行为。快手主流量上线.
#摘要
终身用户行为建模中,SIM、UBR4CTR 等两级级联框架达到 SOTA: 用简单快速的 GSU 从海量行为中检索与目标最相关的少量行为,再用注意力 ESU 在这些 finalist 上做 Target Attention (TA)。但它们有个根本局限: GSU 与 ESU 的目标-行为相关性度量不一致,导致 GSU 经常漏掉 ESU 高度认可的行为,限制了整体 CTR 精度.
本文提出 TWIN (TWo-stage Interest Network): 其 Consistency-Preserved GSU (CP-GSU) 采用与 ESU 中 TA 完全相同的目标-行为相关性度量,让两阶段成为 “双胞胎”。为把昂贵的 TA 扩展到长达 的序列,设计了基于行为特征拆分的新注意力机制: 对视频固有特征,用预计算与缓存策略简化线性投影; 对用户-物品交叉特征,把每个压成注意力分中的一维偏置项。两阶段一致性 + CP-GSU 中有效的 TA 度量带来了显著提升,已部署于快手主流量 (3.46 亿日活).
#1。引言
工业终身行为建模算法大多遵循两个级联阶段:
- GSU 从海量行为中检索与目标最相关的少量行为
- ESU 在这些 finalist 上做 Target Attention (TA)
这样设计的理由有两方面:1。为了精准捕捉用户兴趣,TA 是强调目标相关行为并抑制目标无关行为的合适选择。2。TA 的计算成本高昂,限制了其适用的序列长度最多为几百。工业界用户行为序列几个月就能达到 1w~10w 长度,为此,作为预过滤器的 GSU 非常重要。
近年来,关于两阶段终身行为建模的研究有几条路线,其关键区别在于 GSU 选择。例如:
- SIM Hard 选同类目行为,SIM-Soft 通过内积计算预训练物品嵌入中的目标-行为相关性分数,并选择相关性最高的行为。
- ETA 用 LSH 哈希 + 汉明距离近似相关性分数计算。
- SDIM 通过多轮哈希碰撞采样与目标行为具有相同哈希签名的行为
仍然存在一个关键局限性:GSU 与 ESU 之间的不一致性。

图 1。传统两级算法中 GSU 与 ESU 的不一致。假设有个 “Oracle” (蓝) 能用与 ESU 相同的度量在全部- 行为上检索,即找出 “真正的 Top-100”。而 GSU (橙) 用低效且不一致的粗搜: 它返回的 Top-100 里 (x 轴),只有 40 个命中真正的 Top-100 (y 轴)。这块不一致 (灰色) 就是改进空间.
TWIN 的核心思想: 把 TA 结构扩展到 GSU,并把 ESU 的 embedding 与注意力参数同步到 GSU,保持端到端训练。这样实现了网络结构与模型参数双重一致,相比 ETA / SDIM 有显著提升.
#2。相关工作
#2.1 CTR 预估
1。FM & FFM 2。WDL, DeepFM, DCN, xDeepFM, AFM 3。用户行为建模: DIN, DIEN, DSIN, MIND, DMIN, BST, BERT4Rec
#2.2 长期用户行为建模
随着在当代工业推荐系统中验证了 TA(主题关联)和兴趣建模的有效性,研究人员开始对越来越长的行为进行建模。
- MIMN (记忆网络): 难扩展到 以上, 且对不同候选生成同一个 memory, 带噪声、损害 TA.
- SIM / UBR4CTR (两级检索): UBR4CTR 用 BM25; SIM-Hard 选同类目行为, SIM-Soft 用预训练 embedding 内积。两级设计是大进步, 但 GSU 计算负担仍重, 检索度量与 ESU 不同 → 两阶段不一致.
- ETA / SDIM (端到端): ETA 用 LSH 哈希 + 汉明距离, SDIM 用多轮哈希碰撞采样。优点是 End2End (两阶段共享 embedding), 但检索策略 (网络结构与参数) 仍不一致.
#3。TWIN 模型
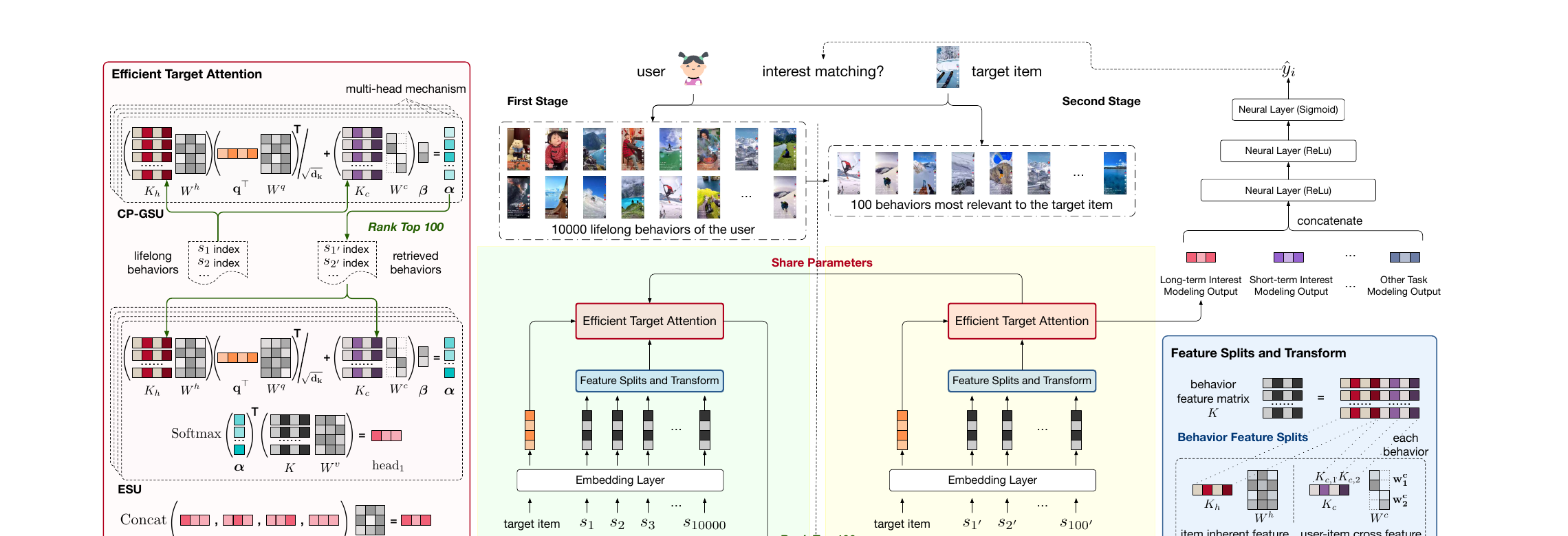
图 2。快手 CTR 系统中的 TWIN。与传统两级算法不同,TWIN 在 CP-GSU 与 ESU 中采用完全相同的目标-行为相关性度量 – 不仅网络结构相同 (左),参数值也相同 (中下)。难点在于 MHTA 计算成本高,原本只适用于 ESU (100 行为) 而非 CP-GSU ( 行为)。解法: ① 对固有特征与交叉特征分别处理的高效特征拆分与投影 (右下); ② 把交叉特征压成偏置项,简化目标注意力架构 (左).
整体 CTR 模型由三个中间模块拼接后送入上层 MLP:
- TWIN: 一致性保持的终身行为建模,含 CP-GSU (从数万行为粗筛 100 个) + ESU (在 100 个 finalist 上做精确 TA);
- 短期行为建模: 对最近 50 个行为建模,补充短期兴趣;
- 其他任务建模: 性别/年龄/职业/地理,视频时长/话题/热度,上下文等.
#3.1 行为特征拆分与线性投影
MHTA 的瓶颈在于注意力分计算中对行为矩阵 的线性投影。 TWIN 把长度 的行为序列特征矩阵 拆成两部分:
- – 固有特征 (video id、作者、话题、时长),与具体用户/行为序列无关;
- – 用户-物品交叉特征 (点击时间戳、播放时长、点击页面位置、用户-视频交互).
固有特征: 虽然维度 大 (每个 id 特征 64 维),但固有特征在用户间共享,配合缓存策略, 可由 “查表 + gather” 高效得到 (离线预计算).
交叉特征: 不能缓存 (描述用户与视频的交互,用户间不共享; 且每个视频每人最多看一次,投影无重复计算)。于是简化投影权重 – 给定 个交叉特征 (每个 embedding 8 维,):
其中 是第 个交叉特征的切片, 是其投影权重。这把每个交叉特征压成 1 维 (),等价于把 限制成分块对角矩阵.
#2.3 计算复杂度
原始 MHTA 投影是。
TWIN 中 预计算后 gather 仅, 降到。
由于 且,正是这个加速让 MHTA 能在 CP-GSU 与 ESU 中一致地实现。
#2.2 TWIN 中的目标注意力
设目标物品固有特征为,经投影 后,目标与历史行为的相关性分 统一定义为 (CP-GSU 与 ESU 共用):
即固有特征做内积 (query 与 key),交叉特征压成 1 维后作为偏置项, 是交叉特征相对重要性的可学习参数.
- 在 CP-GSU: 用 把 的长期行为砍到 100 个最相关的;
- 在 ESU: 对 100 个 finalist 做加权平均池化:
ESU 的 只在 100 个行为上做,在线可高效完成,无需像算 (针对 行为) 时那样拆分.
多头: 采用 4 个头:
#2.3 在线部署与加速
部署于快手排序系统 (3.46 亿日活,峰值 3000 万视频/秒):
- 近线训练: 每天 460 亿条日志,每条在 8 分钟内被采集预处理用于增量训练; 参数每 5 分钟同步到推理/服务系统.
- 离线推理 (固有特征投影器): 用最新参数循环预计算 80 亿候选视频的 (各 head),每 15 分钟刷新一次,把结果存入 KV embedding server。80 亿 key 覆盖 97% 的在线请求.
- 在线服务: 收到请求后查,实时算 的其余部分,选 Top-100 送 ESU。这把 CP-GSU 的瓶颈 ( 行固有特征的线性投影) 削减了 99.3%。由于 ESU 只有 100 行为,可用最新参数实时算,其 甚至比 CP-GSU 更新更及时,进一步提升效果.
#3。实验
数据集: 快手工业数据集 (现有公开集行为太短 – Amazon 人均 <10、Taobao ≤500)。3.46 亿日活,人均近 6 个月看 14,500 个视频,最大序列截断到 100,000.
Baseline: Avg-Pooling、DIN (仅最近 100 行为)、SIM Hard (37 类目)、ETA (LSH+汉明距离)、SDIM (哈希碰撞采样)、SIM Cluster (1000 簇) / SIM Cluster+ (10000 簇)、SIM Soft (内积)。两级模型 GSU 输入最近 10,000 行为,检索 100 个给 ESU.
#3.1 离线整体性能 (RQ1)
表 4。与 SOTA 对比 (5 天均值; 该数据集上 AUC/GAUC 提升 0.05% 即足以带来线上收益):
| Method | AUC | GAUC |
|---|---|---|
| Avg-Pooling | 0.7855 | 0.7168 |
| DIN | 0.7873 | 0.7191 |
| SIM Hard | 0.7901 | 0.7224 |
| ETA | 0.7910 | 0.7243 |
| SIM Cluster | 0.7915 | 0.7253 |
| SDIM | 0.7919 | 0.7267 |
| SIM Cluster+ | 0.7927 | 0.7275 |
| SIM Soft | 0.7939 | 0.7299 |
| TWIN | 0.7962 | 0.7336 |
| Improvement | +0.29% | +0.51% |
TWIN 显著超过所有 baseline,尤其是 GSU 不一致的两级 SOTA。值得注意: SIM Soft (内积) 仍是 baseline 中最强的,后续的 ETA / SDIM 并未真正超越它 – 因为它们为了省算力牺牲了检索精度.
#3.2 一致性、序列长度与消融 (RQ2~4)
- 为什么有效 (RQ2): TWIN 的 CP-GSU 命中 “真正 Top-100” 的比例远高于 SIM Hard/Soft,接近 Oracle,验证一致性是关键.
- 序列长度 (RQ3): 序列从 10,000 增长时所有模型都提升,且 TWIN 与 baseline 的差距随长度增大 – 一致的 TA 能更好地利用更长历史.
- 关键组件 (RQ4): 去掉参数一致性 (TWIN w/o Para-Cons)、去掉偏置项 (w/o Bias)、换回原始 MHTA (w/ Raw MHTA) 都会掉点或显著增加推理耗时,证明特征拆分既保精度又提效率.
#3.3 在线 A/B (RQ5)
在快手三个核心场景 (精选页 Featured-Video Tab、发现页 Discovery Tab、上下滑 Slide Tab) 做严格 A/B。短视频场景核心指标是 Watch Time (总观看时长,0.1% 提升即显著)。TWIN 在所有场景都明显超过 SIM Hard 与 SIM Soft,带来可观业务收益.
#4。总结
TWIN 解决了终身行为两级建模的一致性问题:
- CP-GSU = ESU 的双胞胎: 两阶段共用完全相同的 TA (结构 + 参数),让 GSU 检索出的正是 ESU 认为重要的行为,最大化检索有效性.
- 行为特征拆分: 固有特征预计算缓存 () + 交叉特征压成 1 维偏置 (),把 MHTA 从 100 行为扩展到,瓶颈削减 99.3%.
这是首个在两级终身行为建模中实现一致性的工作。它直接补上了 SIM 的短板 – SIM 为了上线选了系统友好但与 ESU 不一致的 hard-search,而 TWIN 用工程优化把一致的 TA 真正搬到了第一阶段。而当序列继续增长到全生命周期 时,则由 TWIN-V2 用聚类压缩接力.
整条兴趣建模主线:
| 论文 | 解决的问题 |
|---|---|
| DIN (KDD’18) | target-aware 注意力,突破定长向量 |
| DIEN (AAAI’19) | 兴趣随时间演化 (GRU + AUGRU) |
| SIM (CIKM’20) | 终身超长序列 (检索式 GSU+ESU) |
| TWIN (KDD’23) | 两级检索的一致性 (CP-GSU = ESU) |
| TWIN-V2 (CIKM’24) | 全生命周期 (聚类压缩) |
#参考资料
- TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou (arXiv:2302.02352,KDD’23)
- TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling (CIKM’24)
- SIM: Search-based Interest Model (CIKM’20)
- ETA: End-to-end Target Attention (arXiv:2108.04468)
- DIN: Deep Interest Network (KDD’18)