[KDD'18] DIN: Deep Interest Network for Click-Through Rate Prediction 论文精读
DIN 是阿里兴趣建模系列的起点,也是推荐领域第一个把注意力机制引入的工作.
传统 Embedding & MLP 模型把用户所有历史行为压成一个固定长度向量 —— 但用户兴趣是多样的,一个定长向量在有限维度下表达力受限。DIN 的洞察是: 面对不同候选广告,用户被激活的兴趣是不同的 (买键盘看的是电子类历史,买衣服看的是服饰类历史)。于是用 local activation unit 对历史行为做 target-aware 的加权求和,让用户表示随候选广告动态变化.
配套两个工程技巧: Mini-batch Aware 正则 (让亿级稀疏特征的 L2 正则算得起) 和 Dice 激活函数 (自适应整流点的 PReLU)。阿里展示广告线上 CTR +10.0%、RPM +3.8%.
#0. 摘要
CTR 预估的深度模型大多遵循 Embedding & MLP 范式: 大规模稀疏特征先映射成低维 embedding,再 group-wise 地变换成固定长度向量,最后拼接喂入 MLP。这种方式把一个用户的多样兴趣压成同一个定长向量,成为瓶颈。
本文提出 Deep Interest Network (DIN),设计一个 local activation unit,针对某个广告,自适应地从历史行为中学习用户兴趣的表示 —— 这个表示向量随不同广告而变化,大幅提升了模型在有限维度下的表达力。此外提出两个训练技巧: mini-batch aware 正则 和 数据自适应激活函数 Dice。 DIN 已部署于阿里在线展示广告系统,服务主要流量.
#1. 引言
在 CPC (Cost-Per-Click, 点击付费) 广告中,广告按照 eCPM (effective Cost Per Mille,每千次点击成本) 来排名。 eCPM 是 bid (出价) 和 CTR (点击率) 的乘积,其中 CTR 是由系统预估得到的。目前的深度 CTR 模型遵循 Embedding & MLP 范式:首先将大规模稀疏输入特征映射到低维嵌入向量,然后以分组方式转换为固定长度的向量,最后将它们连接起来输入到全连接层(也称为多层感知器,MLP)以学习特征之间的非线性关系。与传统的 LR 模型相比,这些深度学习方法可以大大减少特征工程工作,并显著增强模型能力。
但有个根本问题:用户兴趣是多样化的。Embedding & MLP 把所有历史行为聚合成一个固定长度的向量,该向量位于所有用户的表示向量所在的欧几里得空间中。换句话说,用户的多样化兴趣被压缩到一个固定长度的向量中,这限制了 Embedding & MLP 方法的表达能力。强行扩大维度又会带来参数爆炸与过拟合,增加了计算和存储的负担,工业系统难以承受.
DIN 的灵感来自一个观察 —— 用户兴趣具有局部激活 (local activation) 特性: 当判断一个用户会不会点击某广告时,起作用的只是其历史行为中与该广告相关的一部分。因此不必把全部兴趣塞进定长向量,而是针对候选广告“软”搜索相关行为,做加权求和得到自适应的用户表示.
本文的主要贡献:
- 提出深度兴趣网络 DIN,引入局部激活单元对历史行为做 target-aware 加权,用户表示随广告自适应变化,极大提升表达力.
- 提出两个针对大规模深度网络的训练技巧: ① mini-batch aware 正则,省去对亿级稀疏特征做正则的巨大开销; ② Dice 激活函数,考虑输入分布泛化 PReLU.
- 在公开与工业数据集上验证有效性,并已部署于全球最大广告系统之一.
#2. 相关工作
- NNLM
- LS-PLM 和 FM
- Deep Crossing 和 Wide & Deep
- DeepFM
#3. 背景
阿里巴巴广告系统的运行流程:
- 匹配阶段:用户输入查询,系统根据查询和用户历史行为,匹配出候选广告。
- 排序阶段:系统根据候选广告的 CTR 预估,对候选广告进行排序。
#4. DIN 模型
广告系统和搜索的区别在于,用户不会明确表达自己的意图。需要有效的策略来从丰富的历史行为中提取用户兴趣。描述用户和广告的特征是广告系统中点击率建模的基本要素。合理利用这些特征并从中挖掘信息至关重要。
#4.1 特征表示
工业 CTR 数据大多是多分组的类别形式,例如 [星期=五, 性别=女, 看过的类别={Bag,Book}, 广告类别=Book],通常经编码转成高维稀疏二值特征。第 个特征组的编码向量记为, 是该组的维度 (即该组含 个唯一 id), 且:
- 即为 one-hot 编码 (如性别、星期);
- 即为 multi-hot 编码 (如最近看过的类别,用户访问过的多个类目)。
一个样本按组拼接表示为, 是特征组数, 是整个特征空间维度。
例如一个样本可能是:
| 编码向量 | 含义 |
|---|---|
[0, 0, 0, 0, 1, 0, 0] | 星期=五 |
[0, 1] | 性别=女 |
[0, ..., 1, ..., 1, ..., 0] | 类别={Bag, Book} |
[0, ..., 1, ..., 0] | 广告类别=Book |
表1. 阿里巴巴展示广告系统中使用的特征集统计。特征以分组方式由稀疏二进制向量组成。
| 类别 | 特征组 | 维度 | 类型 | 每个样本的非零 ID 数量 |
|---|---|---|---|---|
| 用户画像特征 | 性别 | 2 | one-hot | 1 |
| 年龄段 | ∼10 | one-hot | 1 | |
| … | … | … | … | |
| 用户行为特征 | 访问过的商品 ID | ∼10⁹ | multi-hot | ∼10³ |
| 访问过的店铺 ID | ∼10⁷ | multi-hot | ∼10³ | |
| 访问的类别 ID | ∼10⁴ | multi-hot | ∼10² | |
| 广告特征 | 商品 ID | ∼10⁷ | one-hot | 1 |
| 店铺 ID | ∼10⁵ | one-hot | 1 | |
| 类别 ID | ∼10⁴ | one-hot | 1 | |
| … | … | … | … | |
| 上下文特征 | pid 用户 ID | ∼10 | one-hot | 1 |
| 时间 | ∼10 | one-hot | 1 | |
| … | … | … | … |
#4.2 Base Model (Embedding & MLP)
多数主流深度 CTR 模型 (LR、Wide&Deep、PNN、DeepFM) 都共享同一个 base model 骨架,由 Embedding、Pooling & Concat、MLP 三层组成。
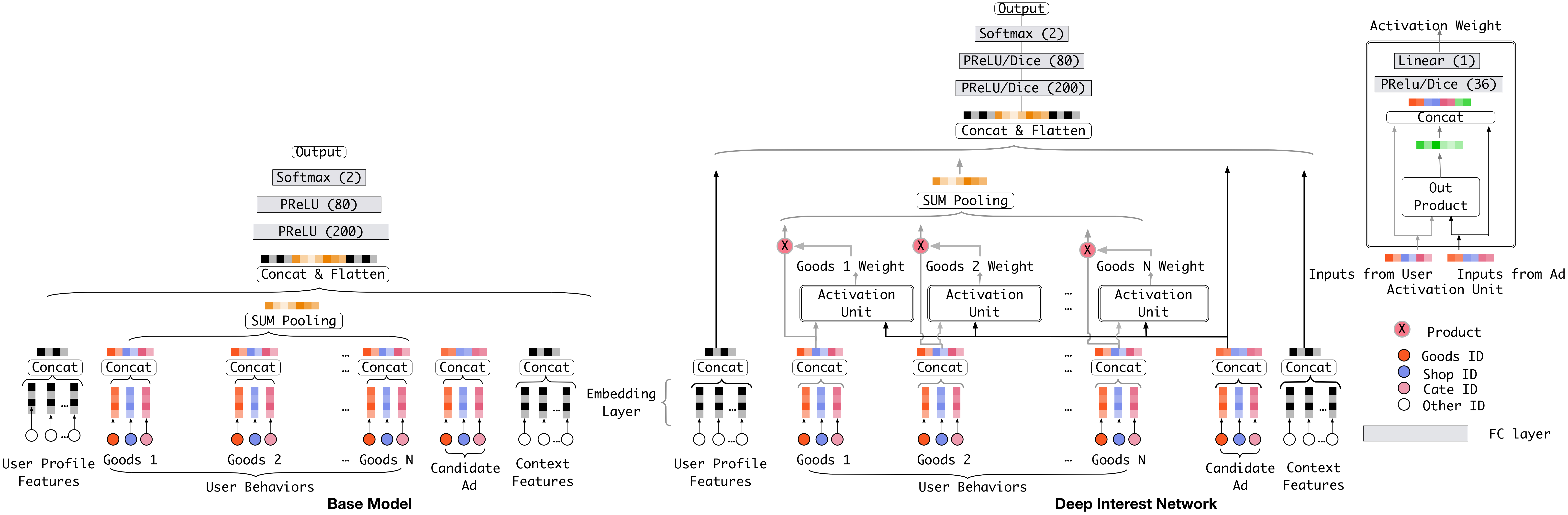
图 2. 网络结构。左: base model,行为 embedding 经 sum pooling 压成定长向量。右: DIN,引入 local activation unit,对每个历史行为算一个相对候选广告的 activation weight,做加权 sum pooling; 其余结构与 base model 相同。
Embedding 层
把高维稀疏的 one/multi-hot 向量 映射成低维稠密 embedding。one-hot 得到单个 embedding 向量,multi-hot 得到一组 embedding 向量的列表。
Pooling 层与 Concat 层
不同用户的行为数不同,导致 multi-hot 行为特征对应的 embedding 列表长度可变,而全连接网络只能吃定长输入。通常会用 sum pooling 和 average pooling (逐元素求和/平均) 把列表压成定长向量:
各组 pooling 后的向量再 concat 成样本的整体表示。
MLP 层
拼接后的稠密向量经全连接层自动学习特征组合。
Loss
目标函数为负对数似然:
其中 是大小为 的训练集, 是标签, 是 softmax 后的点击概率。
#4.3 DIN 的结构
在所有特征中,用户行为特征 对电商场景下的兴趣建模至关重要。base model 用 sum pooling 把用户兴趣 embedding 压成一个固定的表示向量 —— 无论候选广告是什么,这个向量都不变,这正是表达力的瓶颈。
是否有一种优雅的方式,用有限维度的单个向量表达用户的多样兴趣?
DIN 设计了一种局部激活单元来替换 sum pooling。给定用户 的行为 embedding 列表 和广告 的 embedding,用户表示为加权求和:
其中 是一个前馈网络 (activation unit),输出激活权重。除了两个输入 embedding, 还把它们的外积 (out product) 喂入后续网络,作为帮助相关性建模的显式知识。这样 就随不同广告而变化 —— 本质是一种 weighted sum pooling。
1 | # See: https://github.com/zhougr1993/DeepInterestNetwork/blob/master/din/model.py#L200 |
传统注意力要求,但 DIN 放弃了这个约束,目的是保留用户兴趣的强度 (intensity).
例如某用户历史行为 90% 是衣服、10% 是电子产品。面对 T 恤和手机两个候选: T 恤会激活大部分衣服类行为,得到更大的 (更高的兴趣强度),从而 数值更大。传统注意力归一化后会丢失 数值尺度上的分辨率,抹平这种强度差异.
论文也尝试过用 LSTM 按序列方式建模历史行为,但没有提升 —— 因为用户行为可能包含多个并发兴趣,兴趣间的快速跳变让序列显得很 “噪声”。如何用序列结构建模这种数据留作未来工作 (即后续的 DIEN).
#5. 训练技巧
DIN 配套提出两个面向大规模深度网络的训练技巧。
#5.1 Mini-batch Aware 正则化
工业数据含亿级稀疏特征 (如 goods_id 维度 6 亿)。不加正则时,用细粒度 goods_id 特征训练第一个 epoch 后就会严重过拟合,AUC 快速下降。用传统的 L2 和 L1 正则化则不现实 —— 每个 mini-batch 要对整个 embedding 字典 (绝大部分参数) 做更新,计算不可接受。
L2 正则化(L2 regularization),是机器学习里最常用的防过拟合手段之一,核心就一句话:在原来的损失函数后面加一项,惩罚权重的平方和,逼模型把权重压小。
Mini-batch Aware 正则化: 只对每个 mini-batch 中出现的稀疏特征参数计算 L2 范数,让正则计算变得可行。
其中, 是 emb 的维度, 是特征空间的维度,, 是第 个 emb, 表示样本 是否具有特征 ID, 表示特征 ID 在所有样本中出现的次数。
在考虑 mini-batch 的情况下,公式可以简化成:
其中, 表示 mini-batch 数量, 表示第 个 mini-batch。
设 表示 mini-batch 中是否至少有一个实例具有特征,公式可以近似成:
通过这种方式,我们推导出一种近似的感知 mini-batch 版本的 L2 正则化。对于第 个 mini-batch,特征 的嵌入权重的梯度是:
#5.2 Dice 激活函数
常用的 PReLU 以固定的 0 作为整流点 (rectified point):
但当各层输入服从不同分布时,固定 0 整流点不合适。Dice (Data Adaptive Activation Function) 把整流点自适应地设为输入的均值,并平滑切换两个通道:
训练时、 是 mini-batch 的均值/方差; 测试时用滑动平均;。当 且 时 Dice 退化为 PReLU,故 Dice 是 PReLU 的泛化。
#6. 实验
#6.1 数据集和实验设置
| 数据集 | 用户数 | 物品数 | 类别数 | 样本数 |
|---|---|---|---|---|
| Amazon (Electronics) | 192,403 | 63,001 | 801 | 1,689,188 |
| MovieLens | 138,493 | 27,278 | 21 | 20,000,263 |
| Alibaba | 60 million | 0.6 billion | 100,000 | 2.14 billion |
图 4. Alibaba 数据集上 BaseModel 在不同正则化下的性能表现。使用细粒度 goods_ids 特征且无正则化训练时,在第一轮迭代后出现严重过拟合。所有正则化方法均有所改进,其中我们提出的 mini-batch 感知正则化表现最佳。此外,使用 goods_ids 特征训练的模型比不使用时获得更高的 AUC,这源于细粒度特征所包含的更丰富信息。
#6.3 指标
工业场景用用户加权 AUC (论文里仍简称 AUC,即 GAUC),衡量用户内 (intra-user) 排序好坏,与线上表现更相关:
其中, 是用户数量, 和 分别是第 个用户的展示次数和 AUC 值。
并用 RelaImpr 衡量相对提升 (随机猜 AUC=0.5):
#6.4 开源数据集结果
表 3. Amazon(Electronics) / MovieLens AUC (实验重复 5 次取平均值,base 为 BaseModel):
| Model | MovieLens AUC | RelaImpr | Amazon AUC | RelaImpr |
|---|---|---|---|---|
| LR | 0.7263 | −1.61% | 0.7742 | −24.34% |
| BaseModel | 0.7300 | 0.00% | 0.8624 | 0.00% |
| Wide&Deep | 0.7304 | +0.17% | 0.8637 | +0.36% |
| PNN | 0.7321 | +0.91% | 0.8679 | +1.52% |
| DeepFM | 0.7324 | +1.04% | 0.8683 | +1.63% |
| DIN | 0.7337 | +1.61% | 0.8818 | +5.35% |
| DIN with Dice | 0.7348 | +2.09% | 0.8871 | +6.82% |
结论:
- 深度模型全面碾压 LR
- 在用户行为丰富的 Amazon 上 DIN 优势尤其明显 —— 归功于 local activation unit 对相关兴趣的“软”搜索
- Dice 进一步提升
#6.5 正则化性能
由于 Alibaba 数据集包含更高维度的稀疏特征,训练第二个 epoch 就会开始严重地过拟合,导致模型性能严重下降。作者尝试了几种策略:
- Dropout: 随机丢弃样本中 50% 的 fid。
- Filter: 只保留样本中出现次数最多的 N 个
goods_id,本文中保留了 top 20 milliongoods_ids。 - DiFacto 中的正则化: 与频繁特征相关的参数较少被过度正则化,。
- MBA: 本文提出的方法,
表 4. 在 Alibaba 数据集上,BaseModel 在不同正则化下的最佳 AUC,对应图 4。其他所有线条通过与第一行比较来计算 RelaImpr。
| 正则化 | AUC | RelaImpr |
|---|---|---|
| 无 goods_ids 特征,有正则化 | 0.5940 | 0.00% |
| 有 goods_ids 特征,无正则化 | 0.5959 | 2.02% |
| 有 goods_ids 特征,Dropout | 0.5970 | 3.19% |
| 有 goods_ids 特征,Filter | 0.5983 | 4.57% |
| 有 goods_ids 特征,Difacto | 0.5954 | 1.49% |
| 有 goods_ids 特征,MBA | 0.6031 | 9.68% |
#6.6 Alibaba 数据集结果
表 5. 在 Alibaba 数据集上使用完整特征集的模型比较。所有线条通过与 BaseModel 比较来计算 RelaImpr。DIN 显著优于所有其他竞争对手。此外,使用我们提出的 mini-batch aware 正则化器和 Dice 激活函数训练 DIN 带来了进一步的改进。
| Model | AUC | RelaImpr |
|---|---|---|
| LR | 0.5738 | −23.92% |
| BaseModel | 0.5970 | 0.00% |
| Wide&Deep | 0.5977 | +0.72% |
| PNN | 0.5983 | +1.34% |
| DeepFM | 0.5993 | +2.37% |
| DIN | 0.6029 | +6.08% |
| DIN with MBA Reg。 | 0.6060 | +9.28% |
| DIN with Dice | 0.6044 | +7.63% |
| DIN with MBA Reg。and Dice | 0.6083 | +11.65% |
同样激活函数与正则下,DIN 较 BaseModel 有 +0.0059 绝对 AUC / +6.08% RelaImpr; 叠加 MBA 正则与 Dice 后达 +11.65%.
综合来看,带有 MBA 正则化的 DIN 与 Dice 相比,在 BaseModel 上实现了总 11.65% RelaImpr,并获得了 0.0113 的绝对 AUC 提升。即便与在该数据集上表现最佳的竞争对手 DeepFM 相比,DIN 仍实现了 0.009 的绝对 AUC 提升。值得注意的是,在拥有数亿流量的商业广告系统中,0.001 的绝对 AUC 提升具有显著意义,并值得通过经验进行模型部署。DIN 在更好地理解和利用用户行为数据特征方面展现出巨大优势。此外,这两种提出的技术进一步提升了模型性能,为训练大规模工业深度网络提供了有力支持。
#6.7 在线 A/B (2017-05 ~ 2017-06,阿里展示广告)
| 指标 | CTR | RPM |
|---|---|---|
| 提升 | +10.0% | +3.8% |
近一个月的线上 A/B 中,带 MBA 正则与 Dice 的 DIN 较上一版模型 CTR +10.0%、RPM +3.8%,现已全量上线。
为加速在线服务还部署了若干工程技巧 (GPU 加速、请求批处理等).
#7. 总结
DIN 奠定了 “target-aware 注意力建模用户兴趣” 的范式:
- local activation unit: 对历史行为做与候选广告相关的加权求和,用户表示随广告动态变化,突破定长向量瓶颈; 且不做 softmax 归一化以保留兴趣强度.
- 两个工程技巧: MBA 正则让亿级稀疏特征的正则可行; Dice 自适应整流点泛化 PReLU.
DIN 是这条兴趣建模主线的源头,后续工作沿不同方向延伸:
| 论文 | 在 DIN 基础上解决的问题 |
|---|---|
| DIN (KDD’18) | target-aware 注意力,突破定长向量 |
| DIEN (AAAI19) %}</td> <td>行为≠兴趣、兴趣随时间<strong>演化</strong> (GRU + AUGRU)</td> </tr> <tr> <td>{% post_link recommender-system/search-based-user-interest-modeling-with-lifelong SIM |