[AAAI'19] DIEN: Deep Interest Evolution Network for Click-Through Rate Prediction 论文精读
DIN 把历史行为直接当作兴趣, 用注意力激活与 target 相关的行为. 但它有两个盲点:
- 行为只是兴趣的外在表现, 隐藏在行为背后的潜在兴趣没有被显式监督;
- 用户兴趣会随时间演化/漂移 (一段时间爱看书、另一段时间想买衣服), DIN 完全没建模这种动态.
本文 DIEN 用两层结构解决:
- 兴趣抽取层 (Interest Extractor): GRU 建模行为间依赖 + 辅助 loss (用下一个行为监督每一步隐状态), 抽出表达力更强的兴趣序列.
- 兴趣演化层 (Interest Evolving): AUGRU (带注意力更新门的 GRU), 用 target-aware 注意力强化相关兴趣的演化轨迹.
淘宝展示广告线上 CTR +20.7%、eCPM +17.1%.
#摘要
CTR 预估需要捕捉用户行为背后的潜在兴趣; 而且由于外部环境和内部认知的变化, 用户兴趣会随时间动态演化. 现有兴趣建模方法大多把行为表示直接当作兴趣, 缺少对具体行为背后潜在兴趣的专门建模, 也很少考虑兴趣的变化趋势.
本文提出 Deep Interest Evolution Network (DIEN):
- 设计兴趣抽取层从历史行为序列中捕捉时序兴趣, 引入辅助 loss 在每一步监督兴趣抽取;
- 由于兴趣多样, 提出兴趣演化层捕捉与 target item 相关的兴趣演化过程, 把注意力机制新颖地嵌入到序列结构中, 在演化过程中强化相关兴趣的作用.
在公开与工业数据集上 DIEN 显著超过 SOTA. DIEN 已部署于淘宝展示广告系统, 取得 20.7% 的 CTR 提升.
#1. 引言与动机
CPC 计费下 CTR 预估直接影响营收. 大多数深度 CTR 模型遵循 Embedding & MLP 范式:
- WDL、PNN 等关注特征交互, 较少建模用户兴趣;
- DIN 用注意力激活与 target 相关的历史行为, 得到自适应兴趣表示.
但包括 DIN 在内的大多数兴趣模型把行为直接当作兴趣 —— 而潜在兴趣很难直接由行为反映; 同时很少有工作建模兴趣的演化过程.
DIEN 的两点核心设计:
- 兴趣抽取层: 用 GRU 建模行为间依赖. 由于 “兴趣直接引发下一个行为”, 提出辅助 loss 用下一个行为监督每一步隐状态, 让隐状态对兴趣的表示更有针对性.
- 兴趣演化层: 不同 target item 受不同兴趣影响. 用基于兴趣抽取层输出的 AUGRU (GRU with attentional update gate) 建模兴趣演化轨迹 —— 用兴趣状态与 target item 算相关性, 强化相关兴趣、削弱兴趣漂移的干扰. 把注意力引入更新门, 让 AUGRU 对不同 target item 产生不同的兴趣演化过程.
主要贡献: 聚焦电商兴趣演化现象、提出兴趣演化网络; 设计辅助 loss 让 GRU 隐状态更具兴趣表达力; 新颖地设计兴趣演化层, 用 AUGRU 强化相关兴趣并克服兴趣漂移.
#2. DIEN 模型
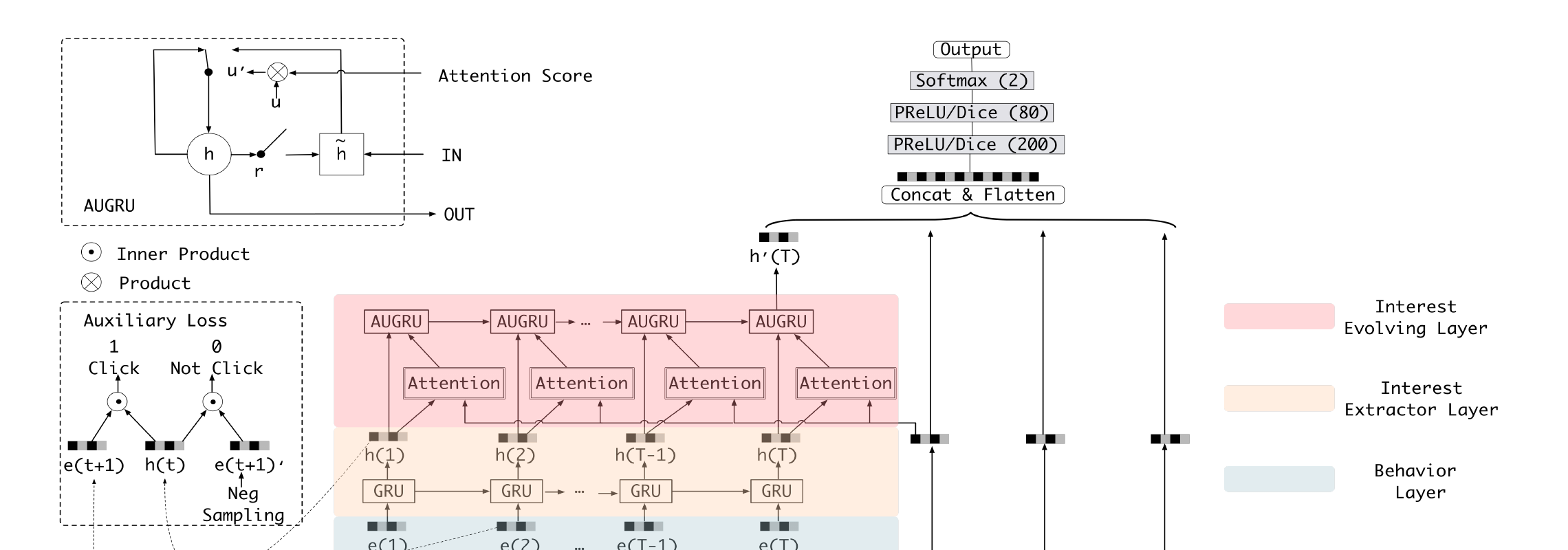
图 1. DIEN 结构. 行为层按时间排序, embedding 层把 one-hot 转成; 兴趣抽取层在辅助 loss 帮助下抽取每个兴趣状态; 兴趣演化层用 AUGRU 建模与 target item 相关的兴趣演化. 最终兴趣状态 与其余特征 embedding 拼接, 送入 MLP 做 CTR 预估.
#2.1 兴趣抽取层 (Interest Extractor Layer)
用 GRU 建模行为间依赖 (兼顾效率与效果, 比 LSTM 快, 避免 RNN 梯度消失):
其中 是第 个行为, 是第 个隐状态,/ 是更新门/重置门, 是逐元素积.
问题: 仅捕捉行为间依赖的 不能有效表示兴趣 —— target item 的点击只由最终兴趣触发, 因此 CTR 的 只监督了最后一步, 历史隐状态 得不到合适监督.
辅助 loss (Auxiliary Loss): 既然每一步的兴趣状态直接引发下一个行为, 就用下一个行为 监督隐状态. 正样本是真实的下一个点击行为, 负样本从除点击外的 item 集合中采样. 设 对行为序列:
其中 是真实下一个点击 item 的 embedding, 是负采样 item 的 embedding, 是作用在内积上的 sigmoid. 全局 loss 把辅助 loss 加权进来:
平衡兴趣表示与 CTR 预估. 辅助 loss 的三重好处: ① 让每个隐状态都能表达兴趣; ② 降低 GRU 建模长序列时的反向传播难度; ③ 给 embedding 层更多语义信息, 学到更好的 embedding 矩阵.
抽取后, 构成兴趣序列, 供兴趣演化层建模.
#2.2 兴趣演化层 (Interest Evolving Layer)
兴趣演化有两个特点: ① 兴趣会漂移 (一段时间看书、另一段时间买衣服); ② 不同兴趣各自独立演化, 我们只关心与 target item 相关的那条演化轨迹.
把注意力的局部激活能力与 GRU 的序列学习能力结合. 第二个 GRU 的输入即兴趣抽取层的兴趣状态:, 最后隐状态 是最终兴趣状态. 注意力分数为:
其中 是广告 (target item) 各 field embedding 的拼接,. 注意力分反映 与广告 的相关性, 越相关分越大.
接下来论文对比了三种 把注意力融进 GRU 的方案, AUGRU 为最终选择:
① AIGRU (Attentional Input GRU) —— 朴素做法, 注意力作用在输入上:
弱相关兴趣的输入被缩小 (理想情况缩到 0). 但即使是 0 输入也会改变 GRU 隐状态, 弱相关兴趣仍会干扰演化学习, 效果不佳.
② AGRU (Attention based GRU) —— 源自 QA 领域, 用注意力分直接替换更新门:
用标量 直接控制隐状态更新, 削弱弱相关兴趣. 但用一个标量替换向量更新门, 忽略了更新门各维度的重要性差异.
③ AUGRU (GRU with Attentional Update Gate) —— 本文方案, 注意力作用在更新门上:
AUGRU 保留更新门 的原始维度信息 (决定各维重要性), 再用注意力分 缩放更新门的所有维度 —— 弱相关兴趣对隐状态的影响更小, 从而更有效地避免兴趣漂移的干扰, 让相关兴趣平滑演化. 最终 与其余特征 embedding 拼接送入 MLP.
#3. 实验
数据集 (表 1): Amazon Books / Electronics 公开数据集, 以及阿里工业数据集 (0.8 亿用户、70 亿样本). 公开集任务: 用前 个行为预测第 个评论.
#3.1 公开数据集结果
表 2. 公开数据集 AUC (重复 5 次):
| Model | Electronics | Books |
|---|---|---|
| BaseModel | 0.7435 | 0.7686 |
| Wide&Deep | 0.7456 | 0.7735 |
| PNN | 0.7543 | 0.7799 |
| DIN | 0.7603 | 0.7880 |
| Two layer GRU Attention | 0.7605 | 0.7890 |
| DIEN | 0.7792 | 0.8453 |
特征交互 (PNN) 优于 BaseModel; 捕捉兴趣的模型 (DIN、Two-layer GRU Attention) 进一步提升; DIEN 既更有效地捕捉时序兴趣, 又建模了与 target 相关的兴趣演化, 提升最大 (Books 上 AUC 0.7880 → 0.8453).
#3.2 工业数据集结果
表 3. 工业数据集 AUC (6 层 FCN: 600/400/300/200/80/2, 行为最大长度 50):
| Model | AUC |
|---|---|
| BaseModel | 0.6350 |
| Wide&Deep | 0.6362 |
| PNN | 0.6353 |
| DIN | 0.6428 |
| Two layer GRU Attention | 0.6457 |
| BaseModel + GRU + AUGRU | 0.6493 |
| DIEN | 0.6541 |
工业数据含各种品类商品, 注意力方法 (DIN) 提升明显, DIEN 建模相关兴趣演化取得最佳.
#3.3 消融: AUGRU 与辅助 loss
表 4. 不同兴趣演化方案 AUC:
| Model | Electronics | Books |
|---|---|---|
| BaseModel | 0.7435 | 0.7686 |
| Two layer GRU attention | 0.7605 | 0.7890 |
| BaseModel + GRU + AIGRU | 0.7606 | 0.7892 |
| BaseModel + GRU + AGRU | 0.7628 | 0.7890 |
| BaseModel + GRU + AUGRU | 0.7640 | 0.7911 |
| DIEN (+ 辅助 loss) | 0.7792 | 0.8453 |
- 演化方案: AIGRU (注意力切分演化, 丢信息) < AGRU (标量替换更新门, 没用足更新门资源) < AUGRU (理想融合注意力与序列学习).
- 辅助 loss: 在 AUGRU 基础上加辅助 loss (公开集负样本随机采样、工业集用曝光未点击作负样本), 进一步把 AUC 从 0.7640/0.7911 拉到 0.7792/0.8453, 提升显著.
#3.4 在线服务与 A/B (2018-06-07 ~ 07-12, 淘宝展示广告)
| 指标 | CTR | eCPM | PPC |
|---|---|---|---|
| 提升 | +20.7% | +17.1% | −3.0% |
服务挑战: 在线高流量、RNN 串行难并发. 用 element-parallel GRU + kernel fusion、行为序列分批截断等工程优化, 把 DIEN 服务延迟从 38.2ms 降到 6.6ms, 满足上线要求.
#4. 总结
DIEN 把 DIN 的 “行为即兴趣” 升级为 “抽取潜在兴趣 → 建模兴趣演化” 两段式:
- 兴趣抽取层: GRU + 辅助 loss, 用下一个行为监督每一步隐状态, 让兴趣序列更具表达力, 也改善了长序列的反向传播与 embedding 学习.
- 兴趣演化层: AUGRU 用 target-aware 注意力缩放更新门, 在保留更新门维度信息的同时强化相关兴趣、抑制兴趣漂移, 得到与 target 相关的最终兴趣.
公开与工业数据集上全面领先, 淘宝展示广告线上 CTR +20.7%、eCPM +17.1%、PPC −3.0%. DIEN 在 DIN 的 target-aware 注意力之上引入了兴趣的时序演化建模; 而面对超长 (终身) 行为序列, 则由 SIM 的检索式范式接力.
#参考资料
- Deep Interest Evolution Network for Click-Through Rate Prediction (arXiv:1809.03672, AAAI’19)
- DIN: Deep Interest Network (KDD’18)
- SIM: Search-based Interest Model (CIKM’20)